这是什么模型?
OWL-ViT是一个开放词汇物体检测模型,给予查询文本query_text或者查询图片,模型可以在目标图像target_image上检测目标。
大致结构
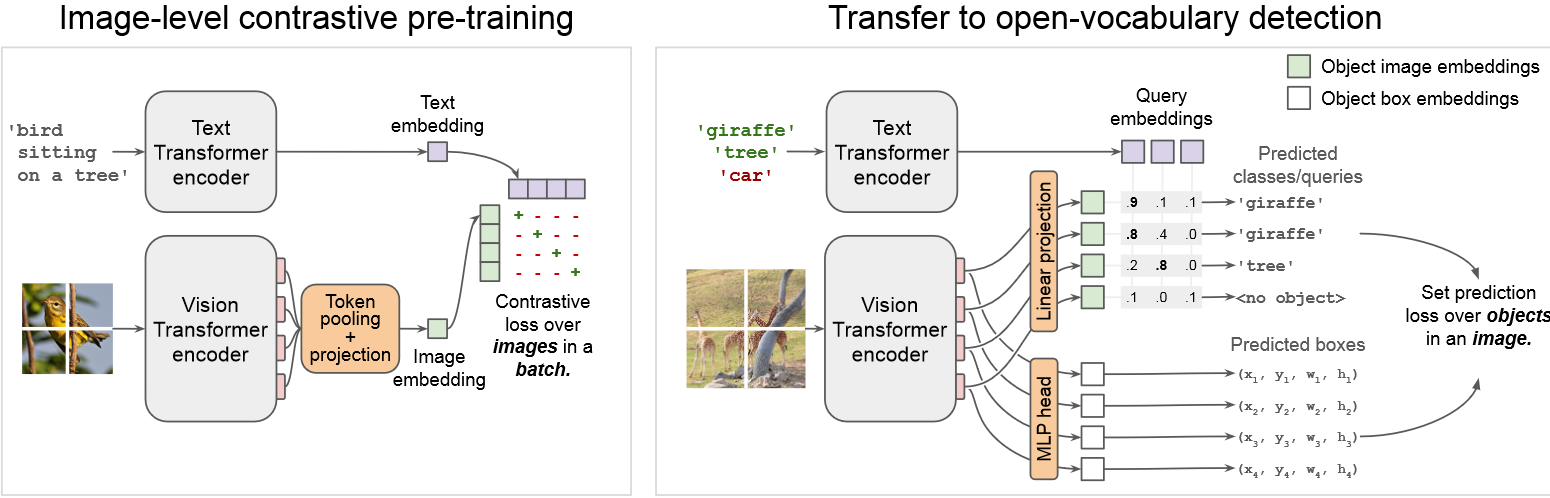
此项工作首先是通过图像文本对去预训练一个图像和文本编码器(左图)类似于CLIP,然后再将预训练的两个编码器放到开放词汇检测模型中(右图),但是去掉了token pooling,添加了linear projection和MLP head两个模块连接到输出。然后再进行find-tuning去优化其余的部分网络。
推理过程
输入输出
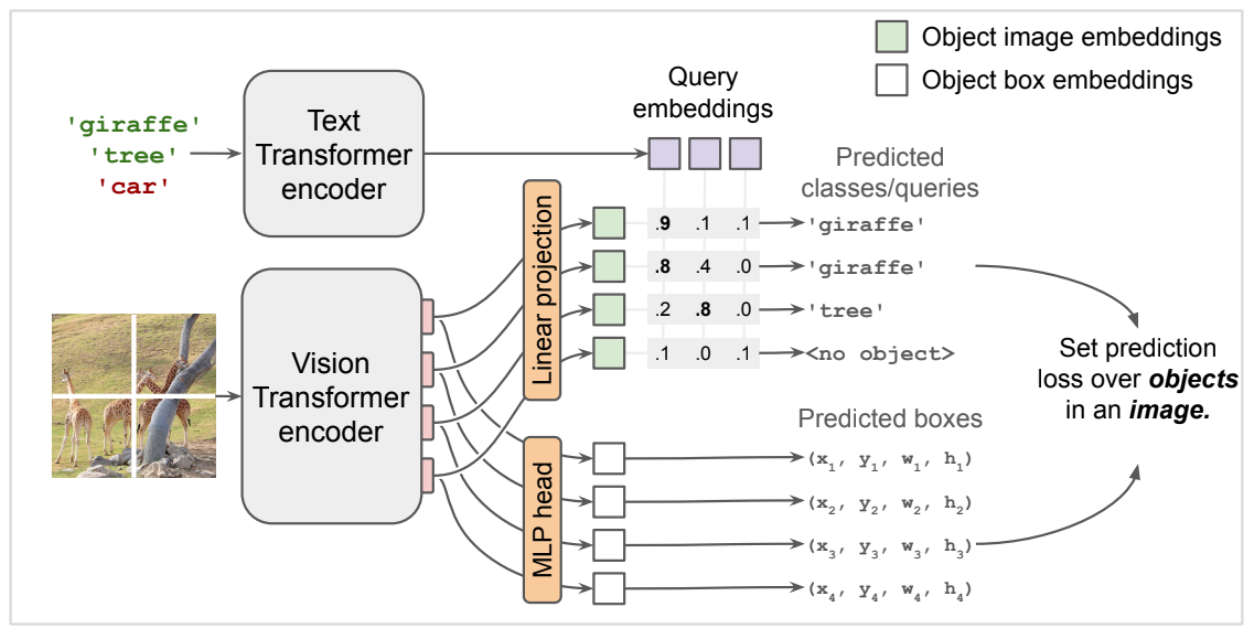
图中展示了模型是如何进行推理的。我们可以看到模型的输入是文本+图片,输出是预测框(predicted boxes)和对应输出框的类别(predicted classes/queries)。
文本编码成向量
对于文本,是经过了一个text Transformer encoder的编码,应该是跟transformer的encoder差不多的结构,将文本转换成向量作为query embeddings。图中三个类别就是三个向量,如图紫色方块。
图片编码成向量
对于图片,是经过 vision transformer的编码器转成向量,就是图中四个粉色的矩形,然后通过线性投影和多层感知机将向量转换到合适的维度上。对于他们的数量,如图有4个patch,就有4个image_imbeddings,4个pred_boxes, 就是图中绿色和白色的矩形。他们之间是一一对应的,代表着检测的一个一个box。而在我使用的模型中,输入图片尺寸是768768,patch 尺寸是3232,因此会有(768768)/(3232)=576个image_imbeddings和pred_boxes。即最大可以有576个盒子。
计算余弦相似度
类似CLIP模型,将得到的query embeddings(紫色方块的向量)和线性投影后的向量(绿色方块的向量)进行点乘,点乘的结果越大说明越相似。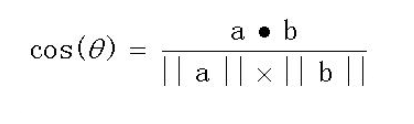
举个栗子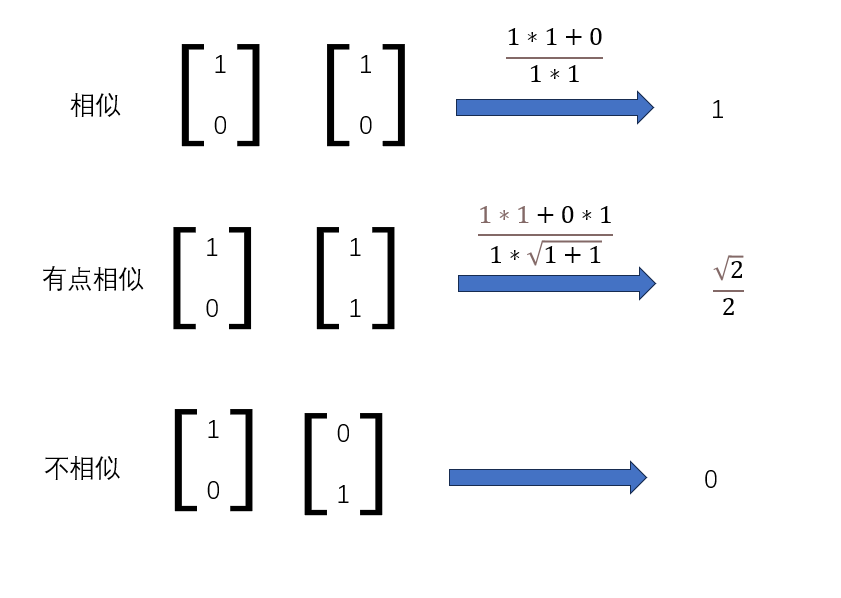
在结构图中的点乘矩阵,第一行最大的数在第一列,说明第一行最有可能是giraffe,所以相应的box(x1,y1,w1,h1)就被预测为giraffe长颈鹿。
第三行的第二列最大,所以box(x3,y3,w3,h3)被预测为tree。
而第四行的每个点乘结果都很低,经过阈值筛选后没有得到结果(no object)。
图像文本编码器的预训练
在大致结构中,我们得知要先预训练两个编码器。首先我们先了解两个编码器的构造。
Text Transformer encoder
这里的文本编码器应该就是普通的transformer编码器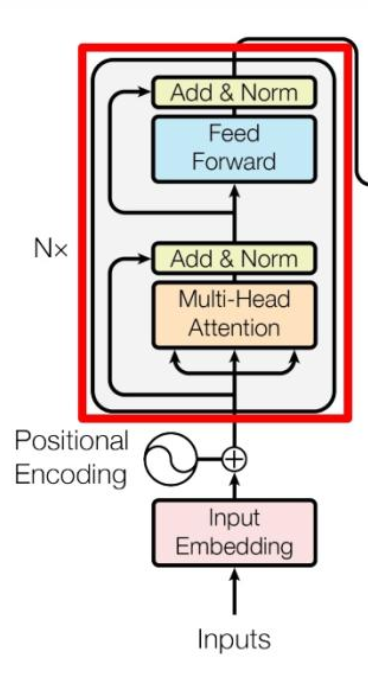
1.将文本单词text2seq之后的向量跟位置向量相加
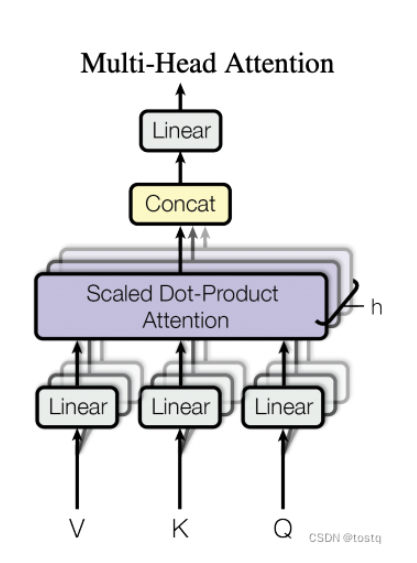
2.进入多头注意力机制
3.把多头注意力的结果和position embedded的输入向量相加并归一化
4.进入Feed Forward 层,这是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数
5.跟第3步相似,也是把进入Feed Forward 层前的向量和Feed Forward 层后的向量相加并归一化。
6.重复N次,得到结果
Vision Transformer encoder
![]()
上图就是vision transformer的分类任务的流程。首先先将一张图片分割成许多个patch,如图所示这里分成了9个。然后将每一个patch图片拍平变成一维的向量通过线性投射层。
举个栗子,patch可以是16x16,那么每个patch维度就是16x16x3=768,然后有9个patch,就是9x768 ,经过线性投影也还是 9x768 ,但是还有特殊字符cls,因此最终的维度是10x768
然后我们需要将patch向量和位置向量相加,不是拼接,维度不变。
然后我们就把这个维度为10x768的向量丢进这个transformer Encoder: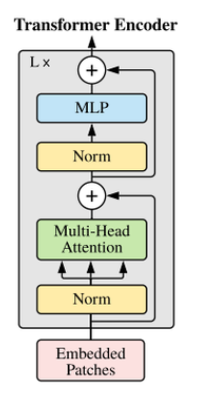
1,首先是将这个向量进行归一化(NORM),然后进入多头自注意力机制中。
2,然后将多头子注意力机制的结果与encoder原输入相加,进行归一化,再经过多层感知机得到结果。
3,然后又将多层感知机的结果跟上一次相加后的向量相加,输出。
4,这个过程重复L次。
从encoder出来之后进入多层感知机,便进行分类。
self attention
上面提及自注意力机制,这里阐述一下过程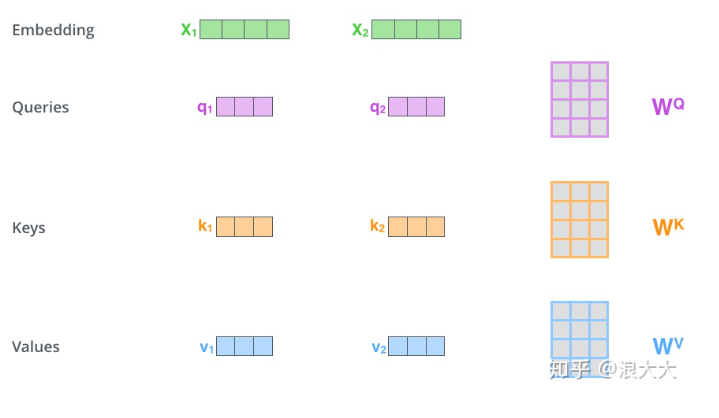
如上图所示,在这里我们的x1,x2就是我们归一化之后的且positon embedded的patches。通过与Wq,Wk和Wv进行矩阵运算之后得到q,k,v。Wq,Wk和Wv 这三个矩阵是我们要训练的东西。我们有10个x,x1~x10。
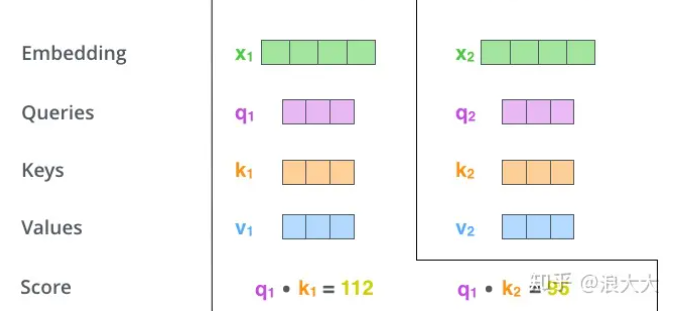
单个q与所有的k进行点乘,得到score
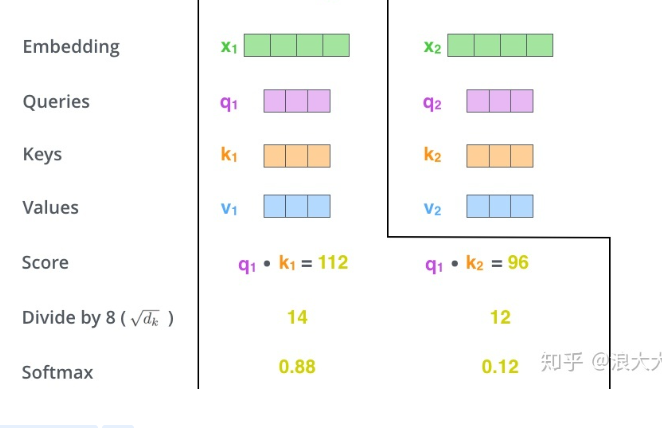
然后我们要将得到的score除以一个数,这个数一般是x矩阵的第一个维度的开方,就是patch数量的开方,我们这应该是根号10。
然后将运算后的结果放到softmax中。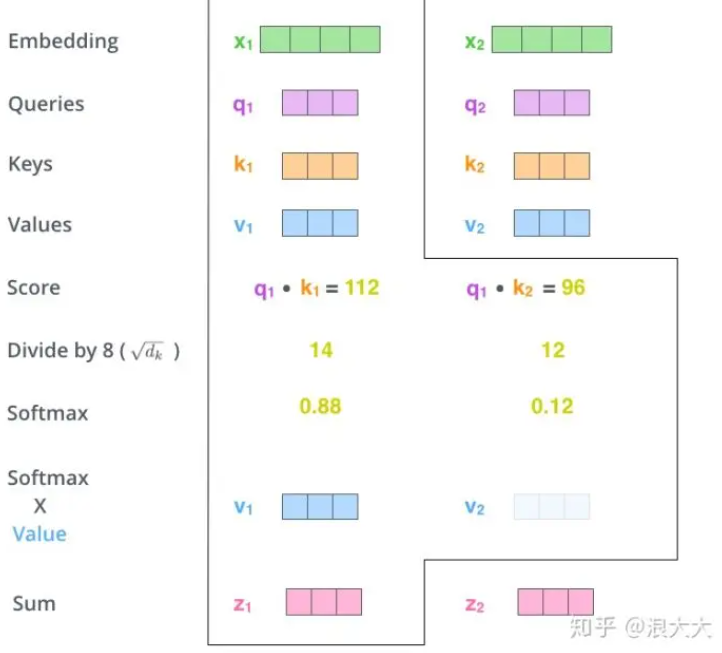
然后把softmax的结果和v相乘。得到v1,v2,v3,v4…v10,再将他们全部加起来得到z1。
最后以此类推,计算出z2,z3,z4… z10,拼接起来得到单个self attention的结果。这个过程可以通过矩阵运算快速得到。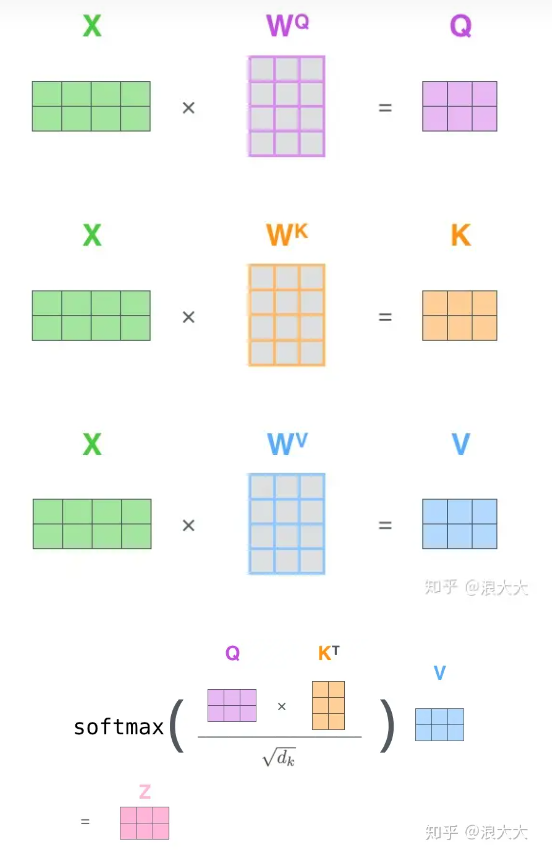
如果是多头自注意力,就是将多个子注意力输出的z向量拼接,然后经过线性变化得到结果。